Anthropic recently introduced the Claude 3 model family, with yet another incremental step forward in AI capabilities. The new family includes three models: Claude 3 Haiku, Claude 3 Sonnet, and Claude 3 Opus, each designed to cater to varying levels of complexity and application requirements, enabling users to choose to match their needs in terms of intelligence, speed, and affordability.
Shiro Welcomes Claude 3
We've already added Claude 3 to the Shiro platform providing access to all currently available Claude 3 models including Opus and Sonnet. We will add Haiku as soon as it is available through the Anthropic API. Shiro enables teams to test out their prompts against Anthropic's models, with direct comparison to any other model provider we offer (OpenAI, Gemini, Mistral, Cohere) on both quantitative and qualitative metrics. If you are interested in learning more about Shiro, request a personalized demo today.
Outperforms GPT-4 and Gemini-1
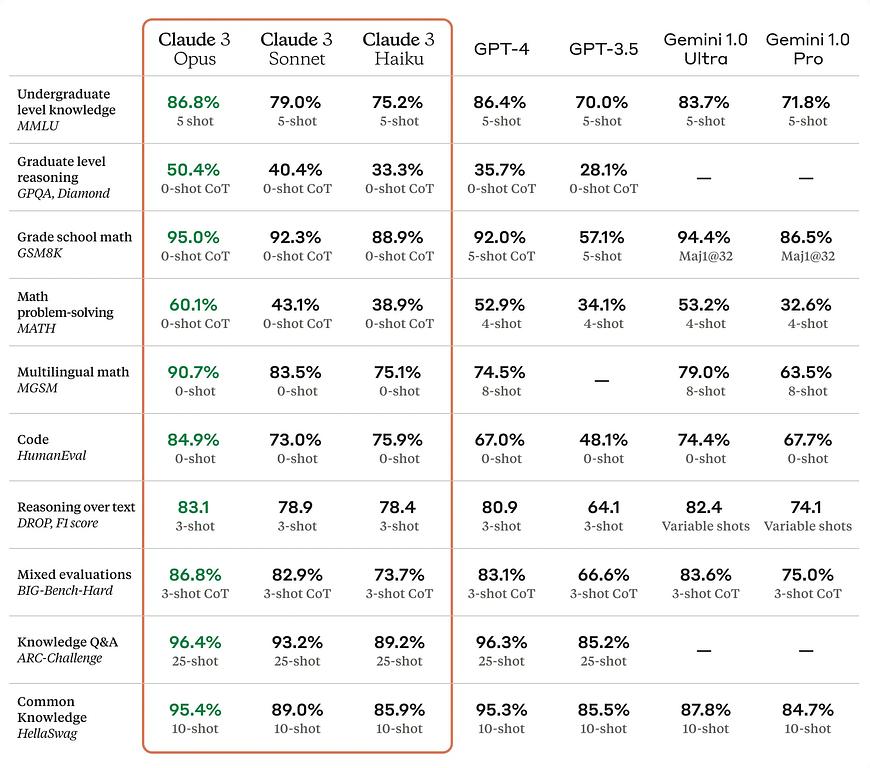
Anthropic's new flagship model, Claude 3 Opus, demonstrates superior performance across a wide array of common AI evaluation benchmarks. According to Anthropic, these benchmarks show Claude 3 inches out both GPT-4 and Gemini-1-Ultra across an array of metrics. Claude 3 Opus enhances capabilities in analysis, forecasting, creative content generation, code creation, and multilingual communication, supporting languages such as Spanish, Japanese, and French.
Claude 3 Metrics Relative to GPT and Gemini (source Anthropic.ai)
Near-instantaneous Responses
The Claude 3 models excel in delivering near-instantaneous responses for applications like live customer chats and data extraction, making them highly suitable for real-time interactions. Haiku, the most rapid and cost-efficient model among the three (but not yet released publically), promises exceptional speed, being able to analyze dense research material in mere seconds. Sonnet offers double the speed of its predecessors, Claude 2 and 2.1, without compromising on intelligence, making it ideal for quick-response tasks. I've tried it on claude.ai and I have to say that Sonnet feels much snappier than ChatGPT.
Visual processing capabilities also show improvement in the Claude 3 models, with the ability to interpret various visual formats. This feature is particularly beneficial for enterprise clients who deal with a significant volume of information in non-textual formats.
Fewer refusals
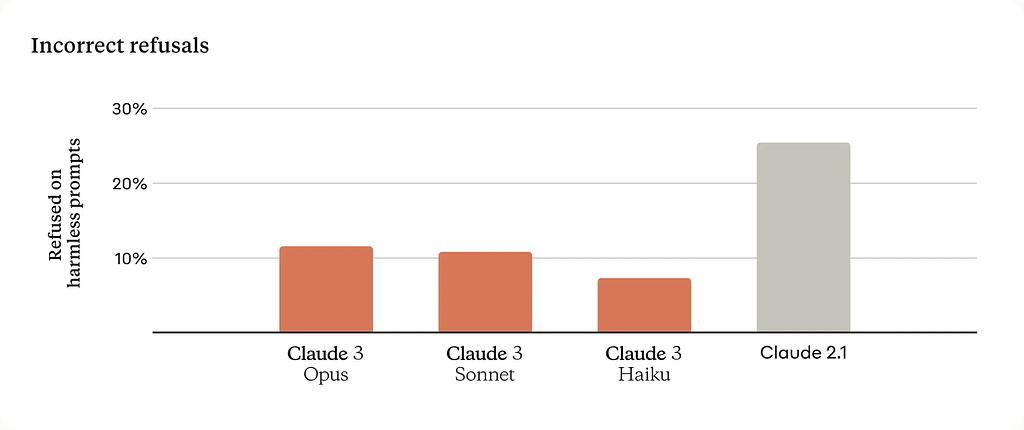
One of the notable improvements in the Claude 3 series is the reduction in unnecessary refusals to respond to prompts, a challenge faced by earlier Claude models. The new models exhibit a better understanding of contextual cues, making them less likely to refuse to engage with prompts.
Refusal Comparison Claude 3 vs Claude 2.1 (source Anthropic.ai)
Better Answers
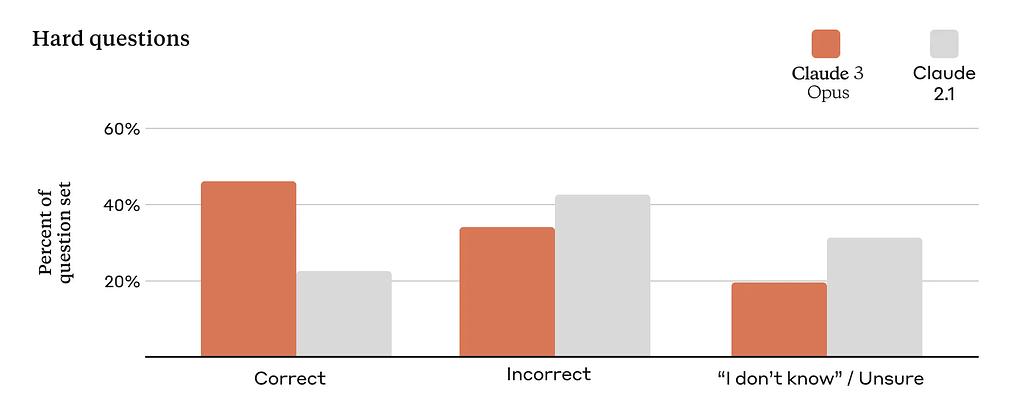
The Claude 3 series demonstrates improvements in providing correct responses to complex, factual questions, reducing incorrect answers and hallucinations. Moreover, the upcoming feature of citation capability in the Claude 3 models is eagerly anticipated, as it will enable the models to reference specific materials to verify their responses.
Claude 3 Opus vs Claude 2.1 on Hard Questions (source Anthropic.ai)
Coding Task Superiority
Anecdotally, yesterday I was using ChatGPT (with GPT-4) and struggling with what typically is a pretty simple task: transforming a set of data from raw text format into CSV format. The data included terms and definitions and was just loosely organized with the term, a line break, the definition of that term, followed by a few line breaks and then the next term. ChatGPT would convert a few lines correctly and then tell me I could do the rest. When asking it to complete the task, it kept have an issue of some type with analyzing the data. I tried multiple attempts including opening new chat windows, trying to get it to use JSON instead of CSV, providing a few shot examples, uploading the text file instead of pasting it etc, but nothing worked.
So I decided to give Claude-3 a try and headed over to claude.ai. Using the free Claude-3-Sonnet I provided the same initial prompt and data and it immediately returned the proper CSV formatted data, with a zero-shot prompt. Keep in mind that Sonnet is supposedly more in line with GPT-3-5 and I was using GPT-4 in ChatGPT. Just one example, but yes Claude-3 appears to be very competitive in my first interaction.
For a more sophisticated view, Paul Gauthier, and independent and well respected AI Coding Benchmarker, just released a new analysis: Claude 3 Opus Outperforms GPT-4 in Real-World Code Editing Tasks. Gauthier's benchmark, based on 133 Python coding exercises, provides a comprehensive evaluation of not only the models' coding abilities but also their capacity to edit existing code and format those edits for automated processing.
The benchmark measures the models ability to interpret instructions and produce code which passes unit tests. If tests fail on the first attempt, the models get an additional chance to use the error output to fix their code.
Gauthier's headline:
Claude 3 Opus outperformed all of OpenAI's models, including GPT-4, establishing it as the best available model for pair programming with AI. Specifically, Claude 3 Opus completed 68.4% of the coding tasks with two tries, a couple of points higher than the latest GPT-4 Turbo model.
The ease of use has also been enhanced, with the Claude 3 models becoming better at following complex instructions and producing structured outputs in popular formats like JSON. This makes the models more versatile for a range of applications, from natural language classification to sentiment analysis.
I am excited to welcome these new Claude-3 models to the Shiro platform and look forward to exploring their capabilities. Shiro enables side-by-side comparisons of prompts across multiple models, so you can compare for yourself how your prompts perform between Claude-3, OpenAI, Gemini, Mistral, and Cohere. If you are interested in learning more about Shiro, request a personalized demo today.
Tan Le
Founder, Software Engineer
Tan is the founder and lead software engineer for OpenShiro. His experience spans multiple industries and technologies, allowing him to approach problems with a unique perspective. Tan holds a Master of Data Science from Deakin University and lives with his wife and two children in sunny Cairns, Queensland. He is passionate about software engineering, artificial intelligence, and entrepreneurship.
Subscribe to our newsletter
The latest prompt engineering best practices and resources, sent to your inbox weekly.